Data Pipes – Wiederkehrende Übertragung strukturierter Daten
Data Pipes sind zuverlässige Verbindungen zum Austausch von Daten zwischen Organisationen, Cloud-Anbietern oder anderen Netzwerkgrenzen. Sie verbergen technische Details und ermöglichen es den Nutzern, sich auf die Semantik der Daten zu konzentrieren. Die wichtigsten Entwicklungsziele sind Einfachheit und Zuverlässigkeit. Man kann sich Data Pipes wie eine Echtzeit-Dropbox für strukturierte, wiederkehrende Daten vorstellen – oder einfach Out-of-the-Box Data Streaming vom Sender zum Empfänger.
Early Access
Das Projekt wird weiterentwickelt – wir suchen technikaffine Partner für die Entwicklung.
Wofür?
Der Austausch von Daten zwischen Systemen und Organisationen ist Voraussetzung für viele datengetriebene Prozesse und Geschäftsmodelle. Er steht im Zentrum der wachsenden Datenökonomie und wird oft als Data Sharing bezeichnet. Doch so einfach ist es nicht: Infrastruktur, Datenmodellierung, Sicherheit, Beobachtbarkeit, Datenkodierung und kontinuierliche Qualitätskontrolle erfordern Spezialisten aus Software-, Daten- und Cloud-Engineering, die eng zusammenarbeiten. Das Ganze ist komplex, teuer und zeitaufwendig – oft nicht machbar für kleine oder nicht-technische Organisationen. Wir brauchen bessere Lösungen.
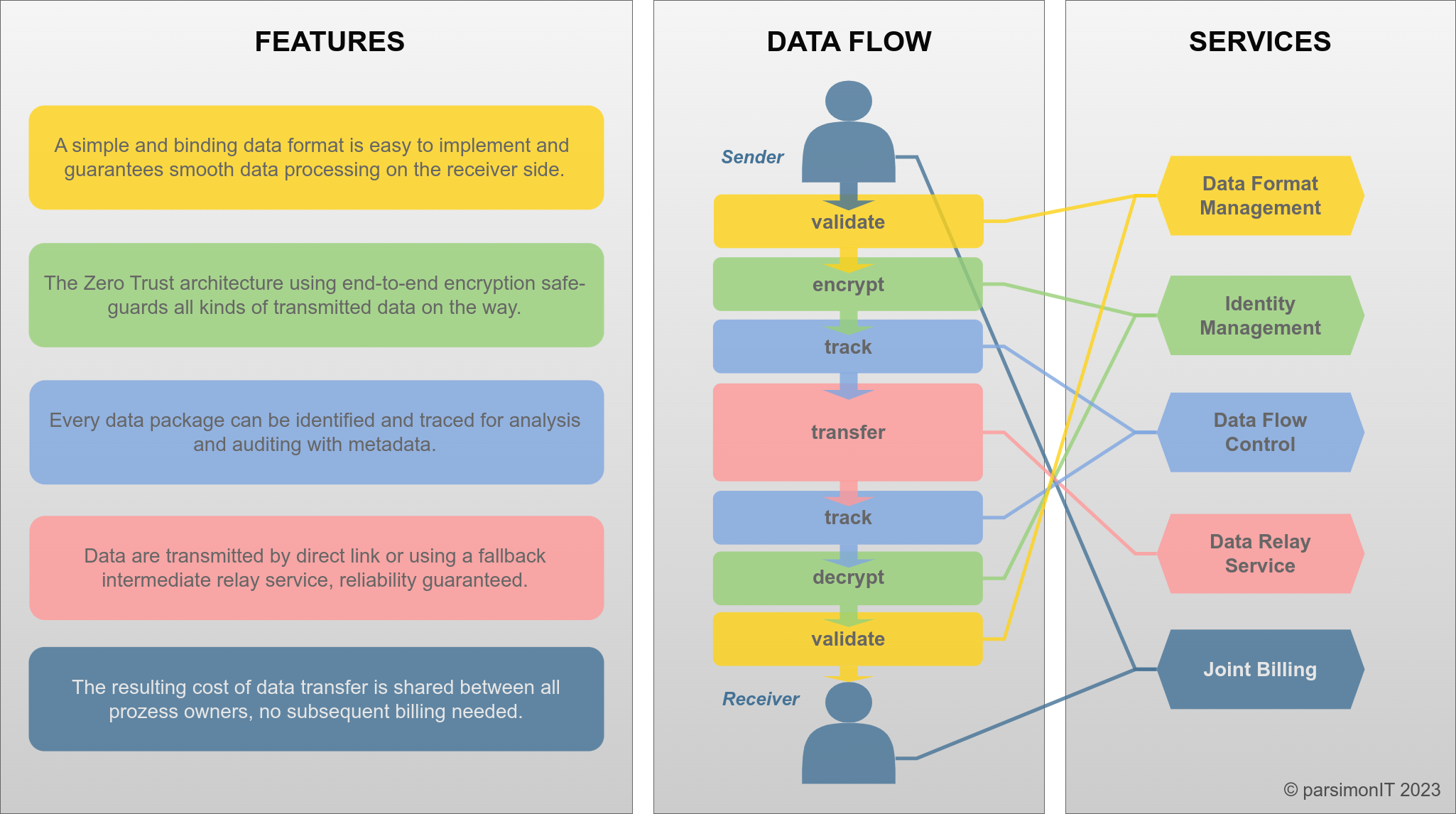
Überblick Data Pipes
Prinzipien
Die Spezifikation sollte so einfach wie möglich sein und komplizierte Syntax vermeiden.
Praktiker wie Data Scientists oder Programmierer sollten Data Pipes wie lokale Daten behandeln – einfach Daten einlesen und schreiben.
Keine dauerhaften Prozesse oder Infrastruktur – das benachteiligt kleine Organisationen und verursacht laufende Kosten.
Keine zeitbasierte Abfrage – stattdessen Benachrichtigung, sobald Daten verfügbar sind.
Daten sind oft kurzlebig. Der Empfänger übernimmt explizit die Verantwortung, der Sender kann nach Bestätigung löschen.
Die Daten werden vollständig verschlüsselt übertragen und sind nur für den Empfänger zugänglich.
Große Daten sollten möglichst im lokalen Netzwerk bleiben, um Zeit und Kosten zu sparen.
Die Gesamtkosten werden zwischen Sender und Empfänger nach Vereinbarung aufgeteilt.
Die Reihenfolge der Datenpakete bleibt erhalten, da sie die Bedeutung beeinflussen kann.
Jede Seite und das Data Pipe Objekt selbst sollten nach Fehlern oder Neustarts den Zustand wiederherstellen können.
Ein Datenpaket sollte identifizierbar und nachvollziehbar sein. Eigentümer sollten jederzeit sehen können, welches Paket wann übertragen wurde. Die Tracking-Datenbank sollte gegen Manipulation geschützt sein und jede Partei sollte sie validieren können.
Jeder Data Pipe Besitzer sollte die Verbindung aussetzen können, um die Kosten auf null zu setzen – z.B. bei abgelaufenem Vertrag oder pausierter Verarbeitung.
Mögliche Anwendungen
- Zuverlässiges Senden und Empfangen von definierten Daten
- Machine Learning mit externen Datenquellen
- Austausch großer wissenschaftlicher Daten mit automatischer Verarbeitung
- Datenübertragung zwischen Verarbeitungssystemen im selben Rechenzentrum oder Cloud-Netzwerk
- Datenfeeds für iterative Verarbeitung
- Zeitabhängige Daten von Sensoren und IoT-Geräten
- Durchsetzung von Datenspezifikationen bei fehlerhaften Datenanbietern (z.B. dezentrale Webformulare)
Data Pipes sind nicht geeignet für
- Verlustbehaftete Datenströme wie Audio oder Video
- Individuelle Abfragen (z.B. Filterung durch Empfänger)
- Mehrere Empfänger und parallele Verarbeitung (muss auf Empfängerseite erfolgen)
- Transformation oder Kombination von Daten unterwegs (muss auf Sender- oder Empfängerseite erfolgen)