Data Pipes - Recurrent streaming of structured data
Data pipes are reliable links to share data across organizations, cloud providers or other network boundaries. They hide all the technical details and let their users concentrate on the semantics of the data. The foremost goals for development are simplicity and reliability. Think of something like real-time Dropbox for structured, well-defined and recurring data, or just out-of-the-box data streaming from sender to recipient.
What for?
Exchanging data between systems and organizations is a prerequisite for many data-driven processes and business models. It is at the core of the growing data economy market and often termed data sharing. Yet, it isn’t as easy as it sounds: infrastructure setup and maintenance, data modeling, data security, observability, data encoding for transmission and continuous data quality checks all call for specialists in the broad fields of software, data and cloud engineering, working closely together on both sides. The whole process is complex, costly and time consuming, which is often infeasible, in particular for small or non-technical organizations and semi-professional individuals. We need better solutions.
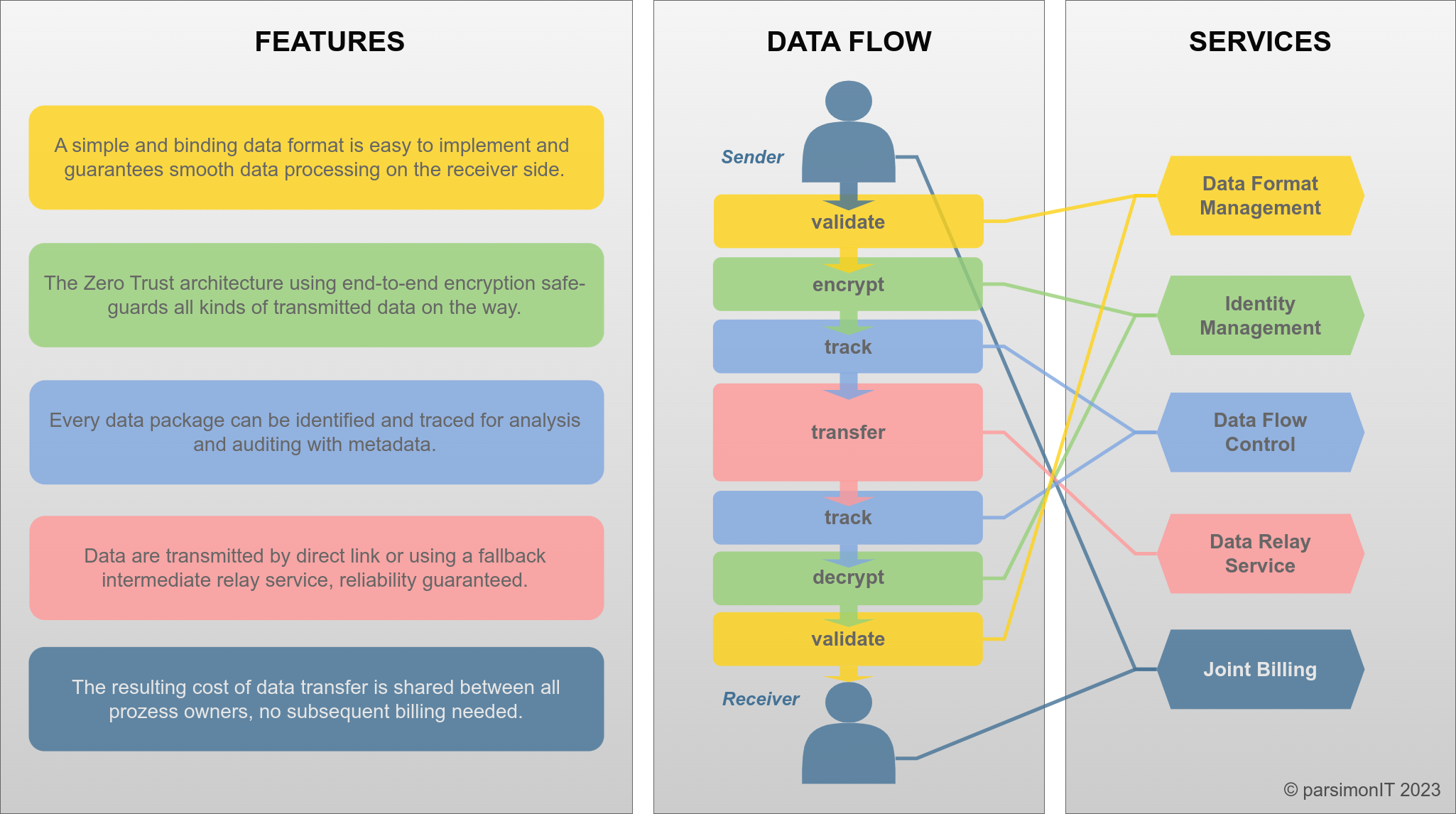
Overview of Data Pipes
Principles
Data specification as a joint task should be as simple as possible and avoid complicated syntax.
Any practitioner working with data on a logical level, such as data scientists or regular programmers, should approach data pipes like they would normally do to read and write data on a local system. After all, it’s just data input and output, like files.
No long-running processes and infrastructure should be required because this discrimiates small organizations and creates continuous costs even when data transfer amounts are small and infrequent.
There should be no time schedule based polling of data because such schedules are error-prone, costly and and delay data processing. Instead, the receiver should be notified once data is available, to start the processing machinery.
Data are often transient and short-lived by nature and may not be worth storing at all. The receiver explicitly takes over responsibility of a data package and the sender may safely delete it after confirmation. This way, although multiple data copies may exist at a time for technical reasons, it’s always clear who’s to hold accountable for data loss.
The actual data should be fully encrypted in transit over the entire route and only be accessible by the receiver and on the receiver infrastructure. No matter whether sending medical, financial or just some logging data, no network and system operator on the way needs not to know about the data content.
Potentially very large data should not leave the computer system or local network, to decrease time and cost.
The total operational cost of data transfers should be split among sender and receiver organization based on an upfront agreement.
The sequential order of data packages should be retained, since it may influence the meaning or processing order of data. Without preserving the order, the sender may have to model the data in a different, more complex way. This simplifies the processing logic on both sides and is irrelevant for naturally unordered data.
Each side including the data pipe object itself should be able to recover from network or system failures, or after processes were simply stopped on purpose. They should continue exactly from the state they terminated to prevent data loss.
A data package should have be identifiable and trackable. Owners should be able to see any time what data package was transferred on which date and time. The tracking database should be resistant to malicious modification and each party should be able to validate it.
Any data pipe owner should be able to suspend a data pipe and thereby set the cost to zero. It can be used as a reaction to an expired delivery contract or when the receiver has temporarily stopped data processing.
Range of possible applications
- The standard case: reliably send and receive well-defined data
- Feeding machine learning algorithms from external data sources
- Sharing large scientific data between research partners with automatic processing
- Transfering data from one processing system to another in the same data center or cloud network
- Turning datasets into data feeds for iterative processing
- Sending time-dependent data from sensors and embedded devices in industry and IoT applications
- Forcing faulty data providers to obey data specifications, even with manual data preparation: think of decentralized web forms
Data pipes are not engineered for
- Streaming lossy data, such as audio or video streams
- Custom queries, for instance when the receiver wants to filter data by specific patterns
- Multiple receivers and parallel computing (you need to redistribute data on the receiver side to do that)
- Transforming or combining data on the way (you need to do that on the sender or receiver side)
Early Access Program
As the project is getting more mature, we are looking for tech-savvy individuals and organisations as development partners. To subscribe to product updates or signal your interest as a future development partner, use this button.